Spark #18 : Spark SQL
Spark ozelliklerini SQL'e benzeyen bir dil ile kullanabilmeyi saglar. Tum sql standardini suan desteklemese de ileride hedef olarak SQL92 standardina uygun olabilmek belirlenmis durumda. Bir ornek:
benimData.createOrReplaceTable("sparkTable")
sqlContext.sql("SELECT * FROM sparkTable WHERE baziStun == 'bazi deger'")
Databricks'teki arkadaslar, spark'in paralel islem gucunu "Big Data" muhendislerinden baska insanlarin da kullanmasini arzu ettiklerini ve SQL adaptasyonuna bu acidan onem verdiklerini soylemisler.
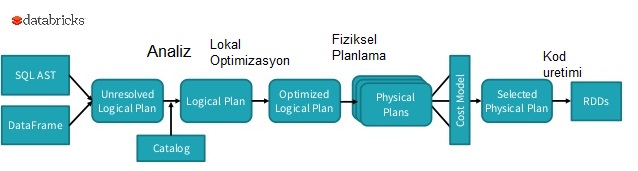
Burada esas amac SQL standardindan da ziyade bir soyutlama katmani yaratmak ve kullaniciya declerative kod yazma imkani saglamak. RDD'ler ile ugrasirken bircok detaya ve islemlerin nasil yapilmasi gerektigine kafa yormak gerekiyor. Ancak SQL ile islerin `nasil` yapilacagini degil de sadece `ne` yapilmasi gerektigini tarif ediyoruz. Gerisi spark tarafindan optimize ediliyor. SparkSQL'e bir alternatif ise Hive'dir. Kisaca bahsetmek gerekirse,
Hive
Cok da programci olmayan analyist gibi ne bileyim data scientist gibi sadece SQL bilen kisilerinde cok buyuk datalardan (petabyte mertebelerine) sorgular yaparak analitik sonuclar cikarabilmesi amaciyla gelistirilmistir. HiveQL isimli sql benzeri bile dili vardir. Geleneksel databaseler (Postgresql gibi mesela) kucuk ve orta olcekteki datalar uzerinde datayi tabular formatta tutarak interaktif mertebede hizli sorgular yapmak icin tasarlanmistir. Cok buyuk datalari islemekte pek basarili degildirler. (Bu konuya ileride deginecegiz ki database'ler horizontal scale konusunda iyi degildir. ) Buna karsilik olarak Hive, batch seklinde calisir. HiveQL daha sonra Hadoop MapReduce ya da Tez job'larina donusturulurler ve distributed dosya sistemleri uzerinde HDFS veya Amazon S3 calistirilirlar. Son olarak da Hive, tablolarla ilgili meta-data, metastore adi verilen bir yerde tutulur.
Ancak yine de gunumuzde SparkSQL cok daha avantajlidir. Gayet guzel optimizasyonlar iceriri:
Predicate pushdown
Bir execution dag icerisinde bircok transformasyon bulunabilir. Lazy yapisi geregi tum transformasyonlar bekletilir ve bir aksiyon geldiginde tumu calistirilir. Bu durumda, bu transformasyonlarin mesela sirasi ile oynamak cok buyuk performans kazanimlari saglayabilir. Ornegin bir parquet dosyasindan 3 Terabyte data okuyup bazi islemler yapip ensonda da bir kritere gore filtreleme yaptigimizi dusunun. Bu sondaki filtrelemeyi eger basta yaparsak, 3Tb data okuman yerine belki cok kucuk bir kismini okumus ve gereksiz okuma yapmamaiz olacagiz. Buna predicate push-down adi veriliyor cunku spark catalyst optimizer, buradaki predicate'i, (yani filtreleyici bir nevi) dag icerisinde daha asagilara, data'ya daha yakin bir yere push ediyor.
Column prunning
Bu da bir onceki optimizasyon gibi, bastan sona tum query incelenerek sadece gerekli stunlarin kaynaktan okunmasini sagliyor. Ozellikle parquet gibi stun bazli (columnar) data formatlarinda ciddi performans getirisi goruluyor.
Bir diger guzellik ise unified bir API ortaya koyuyor olmasidir. 7-8 kisilik bir takimda, low-level RDD 'ler kullanilarak yazilan job'lar gercekten kisiden kisiye gore cok farkettiriyor cunku herkesin bir tarzi var. Ancak sparkSQL ortak bir api ortaya koyarak herkesi esitliyor.
Bir diger performans artisi ise diger dillerin isine yariyor. SparkSQL, sonunda calistirilmadan once JVM Bytecode'a cevriliyor. Bu sayede isterseniz python ise sparkSql gelistirin tamamen ayni performansi aliyorsunuz. Sadece sonuclarin serialize/deserialize noktasinda bir kayip yasanabilir.
Bir ornek yapalim
Case class yapisini kullanarak bir dataframe olusturabiliriz. Case class'lar scala'ya ait bir guzellik olup full serializable bir yapidadir.
> import spark.sqlContext
> import sqlContext.implicits._
> case class Company(name: String, employeeCount: Int, isPublic: Boolean)
> val df = List(
Company("apple", 123, true),
Company("microsoft", 234, true),
Company("kardesler yazilim salonu", 3, false),
Company("zirrto babanin yeri", 5, false)).toDF
seklinde dataframe'mimizi olsuruyoruz. Buradaki toDF metodu, import ettigimiz sqlContext.implicits'ten gelen implicit bir conversion. Arkaplanda aslinda sqlContext.createDataframe(list) seklinde calisiyor.
 |
| df.show metodu ile bir onizleme alabiliriz |
createDataframe metoduna biz case class'tan olusan bir liste push ettigimiz icin hicbir schema belirtmemize gerek kalmiyor. Spark bunu reflaction kullanarak kendisi infer ediyor. Bu da case-class'in Product class'indan turemesinden kaynaklanan bir guzellik.
printSchema metodu ile ayrica da olsuturulan dataframe'deki column yapisi ve bunlarin tipleri hakkinda bilgi alabiliriz.
Simdi de bir dosya okumasi ile dataframe olusturalim. Bunun icin kolpadan bir json dosyasi olusturuyorum. Su sekilde:

Burada json yapisinin bigdata camiasindaki alisik olunan halini goruyorsunuz. Her bir satir bir gecerli json objesi. Ama aslinda tum dosyaya bakarsaniz gecerli bir json degil cunku array gibi bir yapi icerisinde degil. Neyse bu dosyasi okur isek,
> val dfJsonFile = spark.read.json("/mnt/c/data/companies.json")
> dfJsonFile.printSchema
Daha sonra bu iki dataframe'i birlestirmek istersek,
> val dfAll = df.union(dfJsonFile)
ve bir hata ile karsilasiyoruz. Hatada bize diyor ki, ` Union can only be performed on tables with the compatible column types.` Ama ayni schema'ya sahip olmalari gerekiyordu? Ancak oyle degil. Birincisi direk hafizadan olusrutuldugu icin case-class yapisindan infer edilen employeeCount tipi Integer, ama dosyadan okududumuz Dataframe icin bu tipin Long oldugunu goruyoruz. Daha guvende olabilmek icin spark bu stunun tipini Long olarak infer etmis. Dosyadan yapilan okumalarda type inference bazen bu tarz istenmeyen seylere sebep olabiliyor cunku herhangi bir schema tanimlamasi yok. Spark tamamen stunlardaki degerlere bakarak bu stunun tipine karar vermeye calisiyor. Eger bir dosyanin tam anlamiyla istedigimiz tipte okunmasi istersek read spark.read.json(dosya_yolu, schema) seklinde schema tanimlamasi da pass etmemiz gerekiyor.
Ya da simdilik bu tipi cast edip yeni bir dataframe olsuturalim,
> val dfInt = dfJsonFile.select($"name", $"employeeCount".cast("int").as("employeeCount"), $"isPublic")
> val dfAll = df.union(dfInt)
Bu sefer basariyla union edebiliyoruz.
Simdi, halka acik ve acik olmayan isletmelerin toplam calisan sayilarini bulalim. (guzel bir analytics egzersizi, bunu terabaytlarca veri ile yaptiginizi dusunun ve hergun bu sayisis tekrar hesaplamaniz gerekiyor.)
> dfAll.groupBy($"isPublic").agg(sum("employeeCount").as("calisan sayisi")).show

seklinde cok guzel rakamlar elde ediyoruz. (valla rakamlari ayarlamadim kafada salladim).
Bir de filtreleme yapalim. Calisan sayisi 100'den fazla olan sirketleri listeleyelim:
> dfAll.where($"employeeCount" > 100).show
veya cok enteresan bir sekilde, sql seklinde de yazabiliriz:
> dfAll.where("employeeCount > 100").show
Ayrica istedigimiz zaman RDD'ye fallback edebilecegimizi soylemistik. Ancak tek bir sikinti var o da dataframe'in aslinda typed olmamasi.
> val companyNames = dfAll.map(company = company(0).asInstanceOf[String])
Once bu sekilde sadece sirket isimlerinden olusan bir string dataset'i olusturuyoruz. Daha sonra bunu ekrana basabiliriz.
> companyName.foreach(println)
Siquel yazacaktik ?
Tamam tamam. Sql geldi, aslinda hep vardi su ana kadar. Dataframe'leri fluent api ile kullanageldik orneklerde (bkz yukaridaki ornekler). Bunlari direk sql syntax'i ile de kullanabiliriz. Arada hicbir fark yok. Zaten yukaridaki diagrama bakarsak Dataframe ve sql-ast ikisi de ayni ayni seye yani logical-plan'a derleniyor.
> dfAll.createOrReplaceTempView("Companies")
> sql("SELECT * FROM Companies").show
Seklinde cok sevdigimiz sql'imizi yazabiliriz. Yukaridaki ornegi tekrar yaparsak:
> sql("SELECT isPublic, SUM(employeeCount) AS calisans FROM Companies GROUP BY isPublic").show
Vallaha fluent api ile normal sql arasinda gecis yapinca Turkce'den Ingilizce'ye gecmis gibi olunuyormus. En basta yaptiginiz group by islemini SQL'de ensonda yapmak gerekiyor.
Son olarak da, SQL icerisinden de cache'leme yapabiliiz. Hatta lazy ve lazy olmayan sekilde.
> sql("CACHE TABLE Companies")
> sql("CACHE LAZY TABLE Companies")
Birincisinde hicbir aksiyona gerek kalmadan, bu ifade calistirildigi anda tum execution dag calistiriliyor ve sonuc RAM'de cacheleniyor. Digeri iste bildigimiz gibi aksiyon olmasini bekleyen bir cacheleme. Birincisi icin direk bir kullanim alani gelmiyor aklima suanda.
Selametlen.



Yorumlar
Yorum Gönder