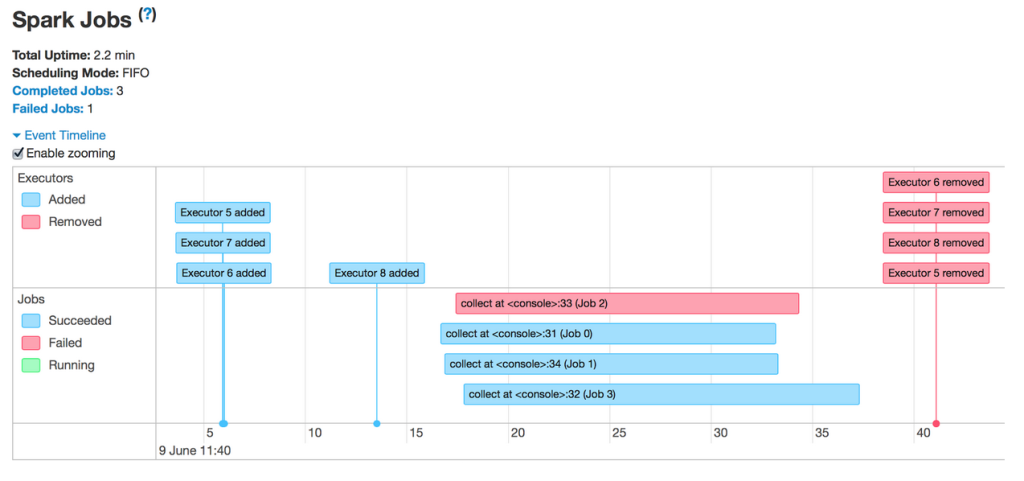
Sbt #3 : Dependency Yonetimi
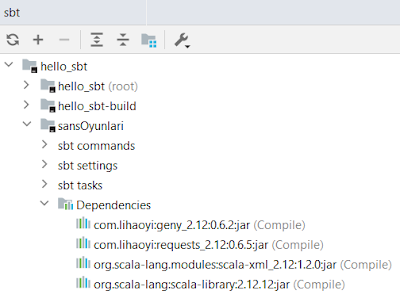
Bu postumuzda sbt ile dependency'ler nasil manage edilir (konustugumz dile bak) konusunu isleyecegiz. Sub-projelerin birbirine depend etmesi soz konusu oldugu gibi 3rd party library kullanimina da deginecegiz. 3rd Party Library Daha once sayisal loto tahmin uygulamasi yapmistik. Simdi buna bir ek yaparak, doviz kurlarini da ekleyecegiz. Bunun icin http request yapmamizi saglayacak scala-request kutuphanesini projeye ekliyoruz. buid.sbt dosyasindaki proje tanimlamasina soyle bir ek yapacagiz: name := "hello_sbt" version := "0.1" scalaVersion := "2.13.4" val sansOyunlari = project.settings( libraryDependencies ++= Seq( "com.lihaoyi" %% "requests" % "0.6.5", "org.scala-lang.modules" %% "scala-xml" % "1.2.0", ) ) Sbt projesini reload ediyoruz. Gidip IntelliJ sbt plugin sekmesine bakarsak su sekilde dependency'lerin olsuturuldugunu gorebiliriz: Simdi requests cal